# 微服务部署
# 开发环境
IDEA
Lombok
EditStarters
Free MyBatis Plugin / MybatisX
Maven Helper
Maven
- 使用阿里仓库和中央仓库,来回切换更新
- settings.xml 不配置任何镜像仓库,默认使用中央仓库
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 https://maven.apache.org/xsd/settings-1.0.0.xsd"> <localRepository>D:\home\java\maven_repository</localRepository> <mirrors> <!--<mirror>--> <!-- <id>alimaven</id>--> <!-- <name>aliyun maven</name>--> <!-- <url>http://maven.aliyun.com/nexus/content/groups/public/</url>--> <!-- <mirrorOf>central</mirrorOf>--> <!--</mirror>--> <!--<mirror>--> <!-- <id>huaweicloud</id>--> <!-- <mirrorOf>*</mirrorOf>--> <!-- <url>https://mirrors.huaweicloud.com/repository/maven/</url>--> <!--</mirror>--> </mirrors> </settings>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23在本地仓库目录中搜索“lastupdate”,删除所有lastupdate文件后再重新更新
找到本地仓库的依赖包,删除后重新更新
复制同学的本地仓库中的依赖包
- 使用阿里仓库和中央仓库,来回切换更新
新工程的 Maven 默认配置:
- File - New Projects Settings - Settings for new projects
springboot版本: 2.3.2.RELEASE
springcloud版本: Hoxton.SR12
# Spring cloud Netflix
- 注册中心
- Eureka
- 配置中心
- Spring cloud config
- 远程调用/负载均衡
- Feign
- Ribbon
- 系统容错、限流
- Hystrix
- 容错:
- 容错的手段:降级
- 限流:
- 限流的手段:熔断
- 数据监控
- Hystrix dashboard / Turbine
- 链路跟踪 Sleuth / Zipkin
# eureka
搭建eureka服务器:
新建 spring 模块:sp05-eureka
添加依赖: eureka server
yml
关闭自我保护模式 主机名:eureka1 针对单台服务器: 不向自己注册 不从自己拉取1
2
3
4
5启动类添加注解:
@EnableEurekaServer用来触发 eureka server 的自动配置
eureka运行机制:
- 注册 客户端应用会一次一次地反复注册,直到注册成功为止
- 拉取 客户端应用每隔30秒,拉取一次注册表,来刷新本地缓存的注册表
- 心跳 客户端应用每隔30秒发送一次心跳 服务器连续3次收不到一个模块的心跳,会删除它的注册信息
- 自我保护模式 由于网络故障,15分钟内,85%服务器出现心跳异常,会自动进入保护模式。 所有注册信息都不删除 等待网络恢复后,会自动退出保护模式,恢复到正常模式 开发调试期间,应该禁用保护模式,避免影响测试
eureka客户端:
修改 2,3,4 模块
依赖: eureka client
yml
服务器注册地址: http://eureka1:2001/eureka1
http://eureka1:2001/eureka eureka子路径,是客户端调用的 api 路径
# 高可用
商品高可用:
在 8001 和 8002 端口,重复启动两个商品服务
命令行参数来设置端口:
# 命令行参数,可以覆盖 yml 配置的端口
java -jar item.jar --server.port=8001
java -jar item.jar --server.port=8002
2
3
4
idea启动配置中,配置命令参数:
- 运行配置的下拉菜单 -- Edit Configuration
- 修改 program arguments,添加参数:
--server.port=8001 - 左边的商品启动配置,复制一份,改成
--server.port=8002
eureka高可用:
- 新建两个profile配置文件:
- application-eureka1.yml
- application-eureka2.yml
- 设置两个 eureka 的启动配置参数:
- --spring.progiles.active=eureka1
- --spring.progiles.active=eureka2
- 客户端应用连接两个eureka服务:
- defaultZone: http://eureka1:2001/eureka,http://eureka2:2002/eureka
# Feign 远程调用、Ribbin 负载均衡和重试
修改 04 项目,完成远程调用
- 添加 feign 依赖
- 启动类注解:
@EnableFeignClients触发 Feign 自动配置,扫描远程调用接口,创建动态代理对象 - 定义远程调用接口
- ItemClient
- UserClient
- OrderServiceImpl ,完成远程调用
Feign 集成 Ribbon:
- 默认启用了负载均衡和重试
Ribbon重试:
调用后台服务失败,可以自动进行重试调用
重试参数:
- MaxAutoRetries - 单台服务器的重试次数,默认 0
- MaxAutoRetriesNextServer - 更换服务器的次数,默认 1
- ReadTimeout - 等待响应的超时时间,默认 1000
测试Ribbon重试:
- 02商品,添加随机延迟代码
- 04调用02,超时失败,会进行重试
# Zuul API 网关
系统的调用入口
- 统一的调用入口
- 统一的权限校验
- 集成 Ribbon
- 集成 Hystrix
统一的调用入口:
新建 spring 模块: sp06-zuul
添加依赖:
- zuul
- eureka client
- sp01
yml
# ** 包含深层子路径 # * 只包含一层路径 zuul: routes: item-service: /item-service/** user-service: /user-service/** order-service: /order-service/**1
2
3
4
5
6
7启动类注解:
@EnableZuulProxy
统一权限校验:
模拟登陆:
http://localhost:3001/item-service/i6juh65g4f3 没有登录,阻止访问
http://localhost:3001/item-service/i6juh65g4f3?jwt=iu5hyg45f34t43y 已经登录,可以访问
- 新建过滤器类 AccessFilter,继承 ZuulFilter
- 按规则实现抽象方法
- 添加
@Component注解
- Zuul 自动配置,会在spring容器中发现过滤器实例,完成自动配置
Zuul集成Ribbon:
- 默认启动 ribbon 的负载均衡
- 默认不启动用重试
- 在最前面网关位置重试,会造成大量服务器压力翻倍
Zuul启用重试:
- 添加 spring-retry 依赖
- yml配置: zuul.retryable=true
Zuul 集成 Hysrix:
默认已经启用了 Hystrix
# Hystrix 容错和限流
- 容错 - 处理远程调用的错误
- 容错的手段: 降级
- 限流 - 由于流量过大造成故障,要限制后台模块的访问流量,减轻压力
- 限流的手段: 熔断
容错、降级:
- 实现 zuul 的接口: FallbackProvider
- 按规则实现抽象方法
- 添加
@component注解 - zuul 会自动配置降级类
限流、熔断:
Hystrix熔断条件,断路器打开条件:
- 10秒20次请求(必须首先满足)
- 50%请求出错,执行了降级
断路器打开后,会进入“半开状态”:
- 尝试向后台模块发送一次客户端调用
- 如果调用成功,会关闭断路器,恢复正常
- 如果调用失败,继续保持打开状态
Hystrix dashboard 仪表盘数据监控:
利用 Actuator 来暴露 Hystrix 的监控日志,Hystrix dashboard会抓取日志,对日志进行分析处理
Actuator
spring提供的一个项目指标工具
- 健康状态
- spring容器中所有的对象
- springmvc 所有的访问路径
- jvm堆内存镜像文件
- hystrix 监控日志
添加 actuator:
添加 actuator 依赖
yml配置
m.e.w.e.i: "*" # 暴露所有的监控指标 m.e.w.e.i: health,beans,mappings # 暴露感兴趣的指标 m.e.w.e.i: hystrix.stream # 暴露hystrix监控日志1
2
3
4
5访问查看所有监控指标的地址:
http://localhost:3001/actuator
搭建 Hyastrix dashboard:
新建 spring 模块:sp07-hystrix-dashboard
添加依赖: hystrix dashboard
yml
允许抓取的服务器列表: localhost1启动类注解:
@EnableHystrixDashboard
- 浏览器访问:
http://localhost:4001/hystrix从http://localhost:3001/actuator/hystrix.stream抓取日志
# Turbine
从多台服务器聚合监控数据,将聚合后的数据交给仪表盘进行处理
新建 spring 模块: sp08-turbine
添加依赖
- turbine
- eureka client
yml
抓取的模块:zuul 为聚合后的数据命名:new String("default")1
2启动类注解:
@EnableTurbine
- 聚合后的日志数据访问路径: http://localhost:5001/turbine.stream
# Spring cloud config 配置中心
集中地管理和维护配置文件
检查Git环境:
- 访问 git 官网下载 git
- 安装 git
- settings -- git -- 配置 git.exe 的路径
准备本地Git仓库:
- 在 springcloud1 工程目录下,新建 config 文件夹
- 复制 2,3,4 的 application.yml 到 config 文件夹
- item-service-dev.yml
- user-service-dev.yml
- order-service-dev.yml
- double shift -- action -- 搜索 create git repository
- 选择 springcloud1 工程目录作为本地的仓库目录
- 如果已经有仓库,不要重复创建,也不不要嵌套创建仓库
- double shift -- action -- 搜索 commit
- 全选文件,填写提交信息,完成提交
本地仓库推送到远程仓库:
- double shift -- action -- 搜索 push
- 点 define remote,粘贴远程仓库地址
防止配置中心的的配置,覆盖本地配置和命令参数:
- override-none = true
搭建配置中心:
新建 spring 模块: sp09-config
添加依赖:
- config server
- eureka client
yml
git仓库的地址: https://gitee.com/账户/仓库 存放配置文件的文件夹: config1
2启动类注解:
@EnableConfigServer
api.http 调用测试
### GET http://locahost:6001/item-service/dev ### GET http://locahost:6001/user-service/dev ### GET http://locahost:6001/order-service/dev1
2
3
4
5
6检查注册表中的注册信息:
config-server
配置中心的客户端应用:
- 添加依赖: config client
- 新建配置文件:
bootstrap.yml- 引导配置,
- 项目启动时,先执行引导配置
- 之后才执行 application.yml 的应用配置
- 引导配置,
- 添加三条配置:
- 连接 eureka
- 设置配置陪着中心的 service id
- 下载配置文件
- 控制台前两行的日志:
- 连接 6001
- 下载指定的配置文件
启动顺序:
- 启动 05 等待05完全启动完成
- 启动 09 等待09完全启动完成
- 检查注册表,有没有 config-server
- 启动 2,3
- 启动 4
- 查看 2,3,4 的控制台,连接6001的日志
- 启动 6
# VMware
16+
Nat网络网段设置成 192.168.64.0:
- 编辑 -- 虚拟网络编辑器 -- 上面选择 VMnet8 -- 左下角修改网段
- 注意: 第四个值是0
虚拟机:
- 课前资料/虚拟机/centos-8-2105.zip 解压缩
- 双击
centos-8-2105.vmx加载虚拟机镜像 - 启动虚拟机
- 按提示选择 “已复制虚拟机”
- 如果看到“硬件不兼容”
- 右键点虚拟机 -- 管理 -- 更改硬件兼容性 -- 选择自己的 vmware 版本
- 登录的用户名和密码都是
root
虚拟机中的基础设置:
- 设置了阿里的 yum 安装源
- 阿里yum安装源最近做了调整,需要重新设置 yum 安装源
- 安装了三个工具: python、pip、ansible
- 两个脚本文件,用来设置 ip 地址
- ip-dhcp: 自动获取ip
- ip-static: 设置固定ip
设置 ip 地址:
./ip-dhcp
# 如果设置ip失败,可以尝试执行下面两条命令,再重新设置ip:
nmcli n on
systemctl restart NetworkManager
# 查看ens33网卡的ip
ifconfig
ifconfig ens33
2
3
4
5
6
7
8
9
10
11
重新设置阿里 yum 安装源:
moboxterm 连接服务器
执行下面操作:
# 备份yum源配置 mv /etc/yum.repos.d/CentOS-Linux-BaseOS.repo /etc/yum.repos.d/CentOS-Linux-BaseOS.repo.backup # 下载阿里 yum 源配置文件 curl -o /etc/yum.repos.d/CentOS-Linux-BaseOS.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo # mirrors.cloud.aliyuncs.com 服务器地址改成 mirrors.aliyuncs.com sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Linux-BaseOS.repo vim /etc/yum.repos.d/CentOS-Linux-AppStream.repo # 注释掉 mirrorlist, # 添加下面一行 baseurl=http://mirrors.aliyun.com/centos-vault/8.5.2111/AppStream/$basearch/os/ yum makecache1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
准备 Docker 服务器:
centos-8-2105 关机:
shutdown -h now克隆 centos-8-2105: docker-base
查看ip
ifconfig1用 moboxterm 连接服务器,上传离线安装文件
- DevOps课前资料\docker\docker-install 文件夹 上传到 /root/ 目录
按照 csdn 笔记安装 docker:Docker(一) - 离线安装 (opens new window) 从第三步开始安装
关闭防火墙
systemctl stop firewalld systemctl disable firewalld1
2
3关机:
shutdown -h now
# Rabbitmq
Docker运行Rabbitmq服务:
克隆 docker base: rabbitmq
设置固定ip:
./ip-static ip: 192.168.64.140 ifconfig # 如果设置ip出错,参考上面 ip 设置,执行两条命令1
2
3
4
5上传文件到 /root/
- DevOps课前资料\docker\rabbit-image.gz
导入镜像:
docker load -i rabbit-image.gz docker images1
2参考 csdn 笔记启动 rabbitmq
- RabbitMQ (opens new window)
- Docker运行rabbitmq
工作模式合理分发消息:
- 使用手动确认模式 消息分发不合理的原因,是服务器不知道消费者有没有处理完消息。 使用手动确认模式,不仅是保证消息被正确处理,也可以让服务器知道消费者有没有处理完消息。
- qos=1 每次只接收1条消息,处理完成之前不接收下一条。 只在手动确认模式才有效。
防止服务器崩溃,消息丢失:
消息的持久化:
- 队列设置成持久队列
- 发送的消息设置成持久消息
常见的面试题:rabbitmq防止消息丢失:
- 手动确认模式 保证消息被正确处理,不丢失消息
- 消息的持久化 防止服务器崩溃丢失消息
# 消息服务使用案例
- BUS 配置刷新 通过Rabbitmq发送刷新指令到各个模块,各个模块接收到指令后执行刷新操作 使用Rabbitmq的主题模式
- Sleuth+Zipkin链路跟踪 Sleuth产生的链路跟踪日志,发送到Rabbitmq, Zipkin从Rabbitmq接收日志 简单模式
- 商城系统,订单流量削峰 商城系统中产生的订单,发送到消息队列, 后台的消费者模块接收并存储订单 简单模式、工作模式
# Spring cloud config + BUS 配置刷新
修改 2,3,4,9
添加依赖:
- bus
- rabbitmq
- binder-rabbit
在 09 中添加 actuator 依赖
yml 配置添加 rabbitmq 连接配置
- 修改 09 的 application.yml
- 修改 config 目录的三个配置文件,提交推送到远程仓库
修改 09 的 yml 配置,暴露 bus-refresh 刷新路径
m.e.w.e.i=bus-refresh1
测试:
GET http://localhost:6001/actuator
查看确认,是否已经暴露 bus-refresh 刷新路径
POST http://localhost:6001/actuator/bus-refresh
观察 2,3,4 的控制台,有没有执行刷新操作
2
3
4
5
# Sleuth + Zipkin 链路跟踪
Sleuth
产生链路跟踪日志的工具
添加 Sleuth 只需要添加它的依赖,0配置
A --> B --> C --> D
日志数据:
A, 87J6H5GF34F, 87J6H5GF34F, true
B, 87J6H5GF34F, OI67U545Y43, true
C, 87J6H5GF34F, U45Y46U56Y3, true
D, 87J6H5GF34F, U545T234264, true
2
3
4
修改 2,3,4,6,添加 sleuth 依赖
链路跟踪日志发送到 rabbitmq:
- 修改2,3,4,6添加依赖: zipkin client
- 单独修改 6,添加 rabbitmq
- rabbitmq依赖
- rabbitmq连接配置
- yml配置发送方式:
zipkin.sender.type=rabbit- 06修改 application.yml
- 2,3,4修改 config 目录的三个文件,再提交推送
启动 zipkin 服务:
在磁盘找到 zipkin 的 jar 文件,地址栏输入 cmd 启动命令行,执行启动命令:
# 旧版本
java -jar zipkin-server-2.12.9-exec.jar --zipkin.collector.rabbitmq.uri=amqp://admin:admin@192.168.64.140:5672
# 新版本
java -jar zipkin-server-2.23.4-exec.jar --zipkin.collector.rabbitmq.uri=amqp://admin:admin@192.168.64.140:5672
2
3
4
5
6
# eureka注册,选择正确网卡、注册ip而不是主机名
选择正确网卡:
使用 bootstrap.yml 在引导阶段来选择网卡
spring:
cloud:
inetutils:
ignored-interfaces: # 忽略的网卡
- VM.*
preferred-networks: # 要是用的网卡的网段
- 192\.168\.0\..+
2
3
4
5
6
7
注册ip而不是主机名:
使用 application.yml 配置
eureka:
instance:
prefer-ip-address: true # 使用ip进行注册
instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}
2
3
4
# 订单流量削峰
导入项目到 rabbitmq 工程:
- 课前资料/elasticsearch/pd-商城项目案例.zip 把 pd\pd-web 文件夹,解压缩到 rabbitmq 工程目录
- pd-web\pom.xml 拖拽到 idea
- 修改 springboot 版本:
2.3.2.RELEASE - 导入项目: 在编辑器中右键 -- add as maven project
- application.yml 数据库连接密码
导入数据库:
sqlyog,右键点数据库的连接 -- 从sql转储文件导入 -- 选择 pd-web 文件夹的 pd.sql
如果导入失败,执行四条sql,增大mysql的缓存区,再重新导入
set global max_allowed_packet=100000000; set global net_buffer_length=100000; SET GLOBAL interactive_timeout=28800000; SET GLOBAL wait_timeout=28800000;1
2
3
4
5
6
7清除数据:
delete from pd_user; delete from pd_order; delete from pd_order_item;1
2
3
4
5
启动 pd-web:
- 右键执行 RunPdAPP
- 启动配置中,设置 working directory 设置成 pd-web 模块文件夹路径
- 重启 RunPdAPP
- 访问
http://localhost - 如果浏览器在下载文件,先清空浏览器缓存再重新访问
订单发送到 rabbitmq:
- 添加 rabbitmq 依赖
- yml 添加 rabbitmq 连接配置
- 配置使用的队列的参数:
orderQueue,持久,非独占,不自动删除
- 使用 spring 的 Queue 对象,来封装队列参数
- 修改 OrderServiceImipl ,完成订单发送
- 注入 AmqpTemplate 工具对象
- 调用它的 convertAndSend() 方法,发送订单
- 这个方法,把订单对象自动序列化变成 byte[] 数组再发送
# 分布式事务
# 业务案例
- pom.xml 继承 order-parent
- yml
- app.name
- port
- eureka
- datasource
- mybatis
- sql语句日志
- 实体类
- Mapper
- Service
- Controller
# 全局唯一id发号器
- 解压到 seata-at 目录
- 文件夹改名:
easy-id-generator - pom.xml 拖拽到 idea,修改springboot版本:2.3.2.RELEASE
- 代码中右键--add as maven project
- 添加
bootstrap.yml application.yml添加 eureka 配置、app.name- 配置 id 生成算法开关:
- 雪花算法 -- false
- segment -- true -- 根据库表中记录的参数来生成id
- 配置数据库连接
# 订单调用发号器、库存、账户
- 启动类添加
@EnableFeignClients - 定义三个远程调用接口:
- AccountClient
- StorageClient
- EasyIdClient
- OrderServiceImpl 中完成远程调用
# 分布式事务
# seata
- 阿里的开源项目
- 一站式分布式事务解决方案
- 支持的事务方案
- XA
- SAGA
- AT
- TCC
# seata at 事务
# 启动事务协调器(TC)
- 从 seata 官网下载 seata server(TC)
- 解压
- 修改三个配置文件
- regiestry.conf 向eureka注册
- file.conf seata server运行日志的存储位置
- seata-server.bat 使用的内存 苹果电脑修改 seata-server.sh
- cmd 中运行 seata-server.bat
- 访问注册表,查看有没有 seata-server
- jdk必须是1.8
- seata server 命令窗口不能关闭
- 抽口中不能选中
# 三个业务模块中添加 seata at 事务配置
- seata 依赖
- 三个配置文件
- application.yml 对事务组命名
- registry.conf 连接eureka,获取 seata server (TC)的地址
- file.conf 事务组对应使用的协调器
- 定一个自动配置类,创建数据源代理对象
- 业务方法上添加注解
- @Transactional -- 控制本地数据库事务(和全局事务无关)
- @GlobalTransactional -- 启动全局事务,只在第一个模块添加
# TCC 事务方案
两个阶段的三种操作:
- 第一个阶段:
- Try 预留资源,冻结数据
- 第二个阶段:
- Confirm 确认资源,使用第一阶段冻结的数据,完成业务
- Cancel 取消资源,把第一阶段冻结的数据,再恢复回去
有侵入的事务方案,所有数据操作都需要自己实现,之前学的业务代码需要调整,底层数据库表结构也要调整。
有些复杂情况下,AT事务方案无法自动进行事务控制,就需要手动控制的事务方案。
# 新建工程,导入无事务版本
- 新建 Empty project 工程: seata-tcc
- seata-at/无事务版本.zip 解压缩到 seata-tcc 工程目录
- double shift --- action -- 搜索add maven project
- 选择 order-parent 的 pom.xml 导入
# 添加 TCC 事务
- seata 依赖
- 三个配置文件
- application.yml 对事务组命名
- registry.conf 连接eureka,获取 seata server (TC)的地址
- file.conf 事务组对应使用的协调器
- 调整数据库表结构
- Mapper 添加新的数据库操作
- ResultHolder,幂等性控制
- 按 seata tcc 的规则,定义 TccAction 接口、实现 用来执行 TCC 三个操作
- TccAction 的三个方法要添加 @Transactional,控制本地事务(和全局事务无关)
- 业务方法中,不再直接执行业务,要改成调用 TccAction 的第一阶段方法,冻结数据
- 第一个模块业务方法上添加 @GlobalTransactional
TCC 的三个方法,
- 第一阶段方法,需要手动调用
- 第二阶段方法,由 seata 的 RM 组件(资源管理器)接收TC指令,然后自动执行
# TCC的两个问题
第一阶段冻结数据失败,第二阶段仍然会执行回滚,可能引起数据混乱
第二阶段,如果运行超时或出错,TC会重试执行第二阶段,
可能会重复的提交数据,或重复的回滚数据,造成数据混乱。
# 幂等性控制
一次操作成功,和多次操作的结果相同
# Rocketmq
# 搭建服务器
克隆 centos-8-2105:rocketmq
设置ip:
./ip-static ip: 192.168.64.141 ifconfig # 如果ip设置失败,参考上面 vmware ip设置1
2
3
4
5上传文件到 /root/
- 分布式事务\rocketmq\
- jdk-8u212-linux-x64.tar.gz
- rocketmq-all-4.9.2-bin-release.zip
- rocketmq-dashboard-1.0.1-SNAPSHOT.jar
- 分布式事务\rocketmq\
根据csdn笔记,搭建rocketmq:RocketMQ (一) 安装 (opens new window)
- 所有文件下载都不用执行
# Rocketmq启动命令
cd /usr/local/rocketmq/
#启动name server
nohup sh bin/mqnamesrv &
#启动broker
nohup sh bin/mqbroker -n localhost:9876 &
#如果需要从配置文件启动 broker:
#nohup sh bin/mqbroker -n localhost:9876 -c conf/broker.conf &
#切换到主目录
cd ~/
#启动管理界面
nohup java -jar rocketmq-dashboard-1.0.1-SNAPSHOT.jar --server.port=8080 --rocketmq.config.namesrvAddr=localhost:9876 &
#查看进程,要包含:name server、broker、jar
jps
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Rocketmq 收发消息api
- 新建Empty project工程: rocketmq-dtx
- 新建 maven 模块: rocketmq-api
- 添加 rocketmq 依赖,从 rocketmq(四) 笔记复制
- 测试消息收发方式:
- 同步消息
- 延时消息
- 顺序消息
- 事务消息
# 可靠消息最终一致性事务
用Rocketmq的事务消息实现
# 导入项目
- seata-at\无事务版本.zip 解压缩到 rocketmq-dtx 工程目录
- 导入 order-parent\pom.xml
- 检查项目jdk和语言版本
# 添加可靠消息最终一致性事务
订单 ----> 账户
用消息服务做异步调用
修改订单
父项目pom.xml添加rocketmq依赖
application.yml
- name server 地址
- 生产者组的组名
添加数据库表tx_table,用来存储本地事务的执行状态
添加实体类 tx_info
添加 TxMapper
用来封装消息数据的工具: AccountMessage(userId, money, xid)
JsonUtil
修改 OrderServiceImpl
- 业务方法中发送事务消息
- 在监听器中执行本地事务、处理事务状态回查
- 修改账户,接收消息执行账户扣减
- yml配置
- name server
- AccountMessage
- JsonUtil
- 新建消费者类:AccountConsumer
- 用注解配置接收消息
- 调用业务方法 AccountService.decrease() 完成金额扣减
# DevOps 开发运维一体化
- 一部分运维工作,要交给开发做
- 开发人员在Docker容器中部署自己的应用运行环境
# Docker
为什么使用Docker
- 提高开发-测试-运维流程效率
- 在服务器上可以大量部署Docker容器,充分发挥服务器的运算能力
什么时候使用
以后部署应用,都要使用Docker部署
Docker基本概念
- 镜像
- 容器
Docker服务器
克隆 docker-base: docker
设置ip
./ip-static ip: 192.168.64.150 ifconfig # 如果设置ip失败,参考上面vmware笔记1
2
3
4
5上传文件到 /root/:
- docker-images.gz
- tomcat文件夹
导入镜像:
docker load -i docker-images.gz
# Elasticsearch
# 搭建 ES 服务器
克隆 docker-base: es
设置虚拟机内存:右键点es虚拟机 --- 设置 --- 内存设置成2G
设置ip:
./ip-static ip: 192.168.64.181 ifconfig1
2
3
4上传文件到 /root/
- pditems 文件夹
- elasticsearch-analysis-ik-7.9.3.zip
- es-img.gz
导入镜像:
docker load -i es-img.gz重启docker系统服务:
systemctl restart docker设置一个系统的底层参数,重启服务器:
echo 'vm.max_map_count=262144' >>/etc/sysctl.conf shutdown -r now1
2
3按照 csdn笔记启动 es 容器:Elasticsearch(一)Docker搭建ES集群 (opens new window)
# 拼多商城搜索条
- 添加 elasticsearch 依赖
- yml配置es服务器地址
- 新建实体类 Item,用来封装 pditems 索引中的数据
- 定义 ItemRepository 数据访问接口
- 添加搜索方法: findByTitleOrSellPoint()
- 分页
- 高亮
- SearchService
- SearchController
- search.jsp
# Kubernetes
- 容器的自动部署管理工具
- 谷歌的开源工具
- 缩写 K8s 或 Kube
# 安装搭建 K8s 集群
辅助安装k8s几群的开源工具:
- 一键安装脚本
- 一步一步手动安装
# 集群方案
- 三台服务器 -- 16G或以上内存
- 两台服务器 -- 8G
# 安装集群
#
克隆 centos-8-2105:k1
设置ip
./ip-static ip: 192.168.64.191 ifconfig1
2
3
4上传文件
- DevOps课前资料\kubernetes\
- images.gz 传到
/root/ - kubeasz-3.1.0.zip解压缩
- kubeasz-3.1.0/
ezdown传到/root/ - kubeasz-3.1.0/
kubeasz文件夹传到/etc/
- kubeasz-3.1.0/
- images.gz 传到
设置内存和cpu
- 右键点虚拟机 --- 设置
- 内存 2G+
- cpu 2块
- 重启服务器:
shutdown -r now
安装docker
# 脚本文件添加执行权限
chmod +x ./ezdown
# 下载所有的离线安装文件,如果文件存在不会重复下载
# 执行脚本文件安装docker
./ezdown -D
# 确认docker安装成功
docker info
2
3
4
5
6
7
8
9
导入测试用的镜像
docker load -i images.gz1k1关机,再从 k1 克隆: k2、k3
- 设置k2和k3的ip:
- 192.168.64.192
- 192.168.64.193
- 设置k2和k3的ip:
启动安装集群过程中使用的临时容器
./ezdown -S1安装方式设置成离线安装
sed -i 's/^INSTALL_SOURCE.*$/INSTALL_SOURCE: "offline"/g' /etc/kubeasz/example/config.yml1配置 191 免密登录192和193
# 生成公钥和私钥 ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa # 公钥复制到所有服务器 ssh-copy-id 192.168.64.191 ssh-copy-id 192.168.64.192 ssh-copy-id 192.168.64.1931
2
3
4
5
6
7
8
9创建集群方案的配置
cd /etc/kubeasz chmod +x ezctl # 新建方案 cs1,会新建cs1文件夹,复制默认的样例配置到cs1文件夹下 ./ezctl new cs11
2
3
4
5
6编辑 cs1 方案的 hosts 文件
vim /etc/kubeasz/clusters/cs1/hosts1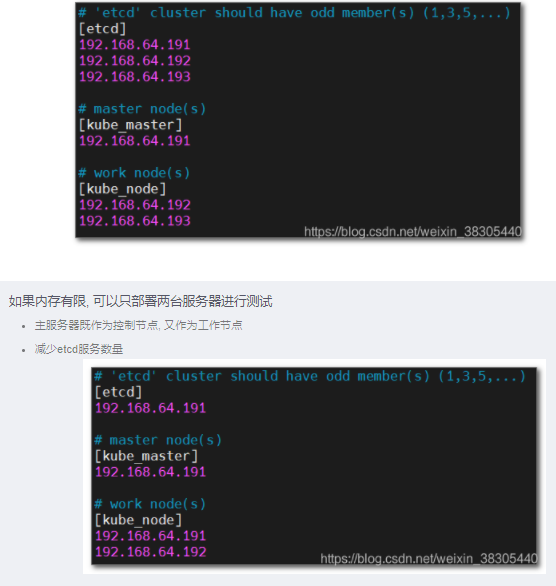
三台服务器拍摄快照,保留当前服务器状态 如果集群安装失败可以恢复到快照状态重新安装
- 可以关闭其他无关应用释放内存
- 或者重启电脑释放内存
- 或者适当增加虚拟机内存
执行一键安装
cd /etc/kubeasz ./ezctl setup cs1 all1
2
3
# K8s三个核心概念
- Pod 是Docker容器的封装对象
- 控制器 用来自动部署或销毁容器
- Service 不变的访问地址
# 小结
# Spring cloud Netflix
- 注册中心 -- eureka,nacos
- 配置中心 -- spring cloud config,nacos
- API网关 -- zuul,gateway
- 远程调用、负载均衡 -- feign、ribbon,dubbo
- 容错、限流 -- hystrix,sentinel
- 数据监控
- hystrix dashboard + turbine,错误监控,sentinel
- sleuth + zipkin,链路监控
# 消息服务
使用场景:解耦、削峰、异步调用
具体项目案例:
- BUS配置刷新
- Sleuth+Zipkin链路跟踪日志
- 订单的流量削峰
- Rocketmq的可靠消息最终一致性事务
Rabbitmq
- 六种模式:简单,工作,发布和订阅,路由,主题,RPC
Rocketmq
- 延时、顺序、事务
# 分布式事务
- Seata
- AT -- 80%场景使用AT事务
- TCC
- Rocketmq 的可靠消息最终一致性事务
- 场景:使用消息服务做异步调用
# DevOps
- Docker
- Kubernetes
# Elasticsearch
倒排索引
概念:索引、分片、副本、映射、类别、文档、字段
Spring data elasticsearch -- Repository
RabbitMQ →